目录概览
- Data Parallelism:每个设备都有完整计算图
- DP
- DDP
- FSDP
- Model Parallelism:不同设备负责计算图的不同部分
- TP
- PP
数据并行
DP
import torch
model = torch.nn.DataParallel(my_model)
- 使用单进程多线程模式(一张卡对应一个线程),会被 python 的 GIL 约束。
- 对整网进行 forward 和 backward 后再进行梯度累计,计算步骤和通信步骤完全隔离,低效。
- 使用基本的 All-Reduce 机制梯度累积,通常 GPU0 作为参数服务器,通信压力集中在一张卡上。
- 不支持多机多卡训练。
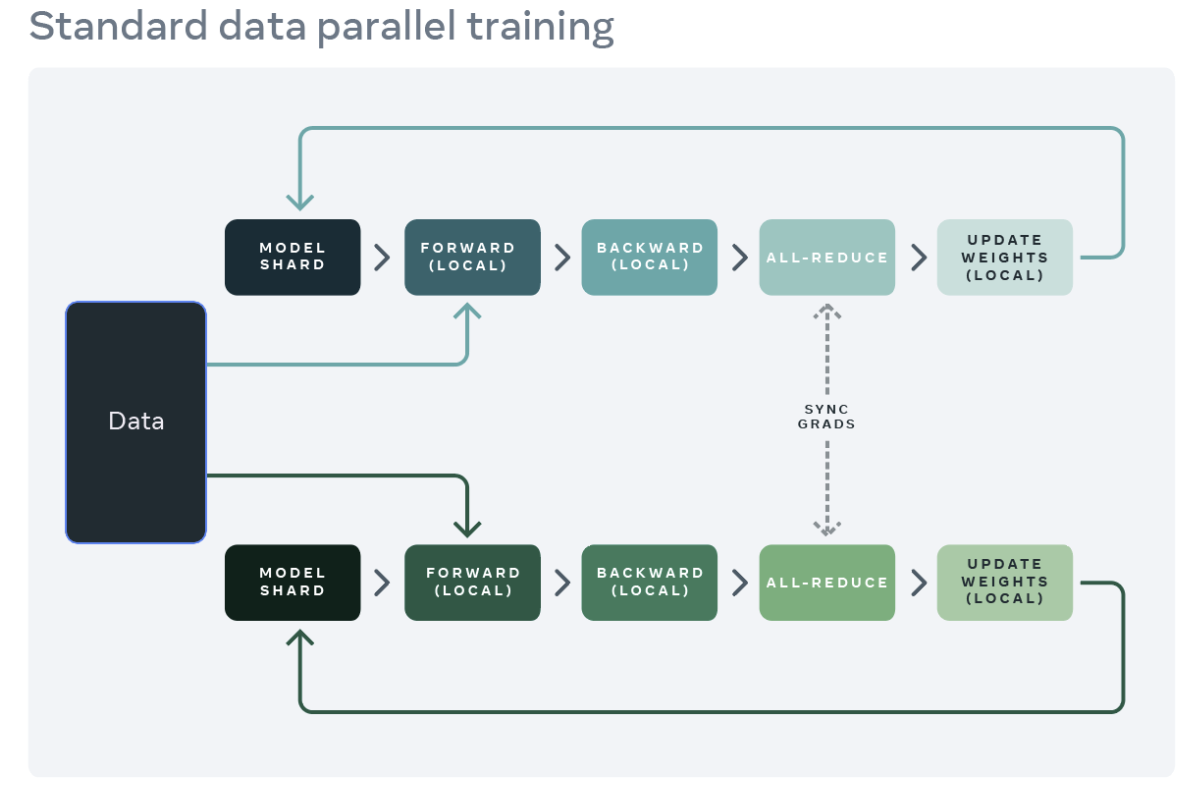
(PS:由于性能问题,现在基本没人用了。)
DDP
from torch.nn.parallel import DistributedDataParallel as DDP
ddp_model = DDP(my_module)
- DDP 发表论文 PyTorch Distributed
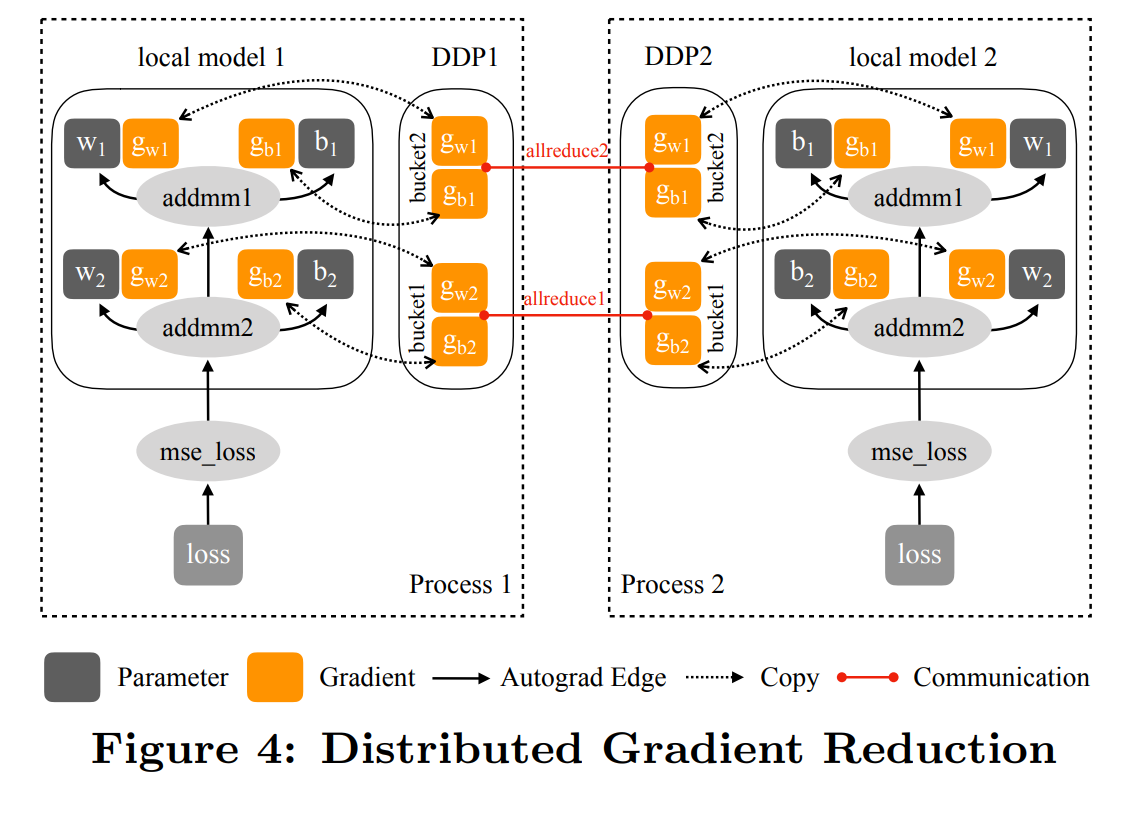
- 基于 Ring-All-Reduce 机制梯度累计,通信压力平均分散在每张卡上。
- 通过分 bucket(包含几个 layer 的参数)的方式,把集合通讯的时间隐藏在了 backward 计算的时间里面。
- 多进程的方式,支持多机多卡。
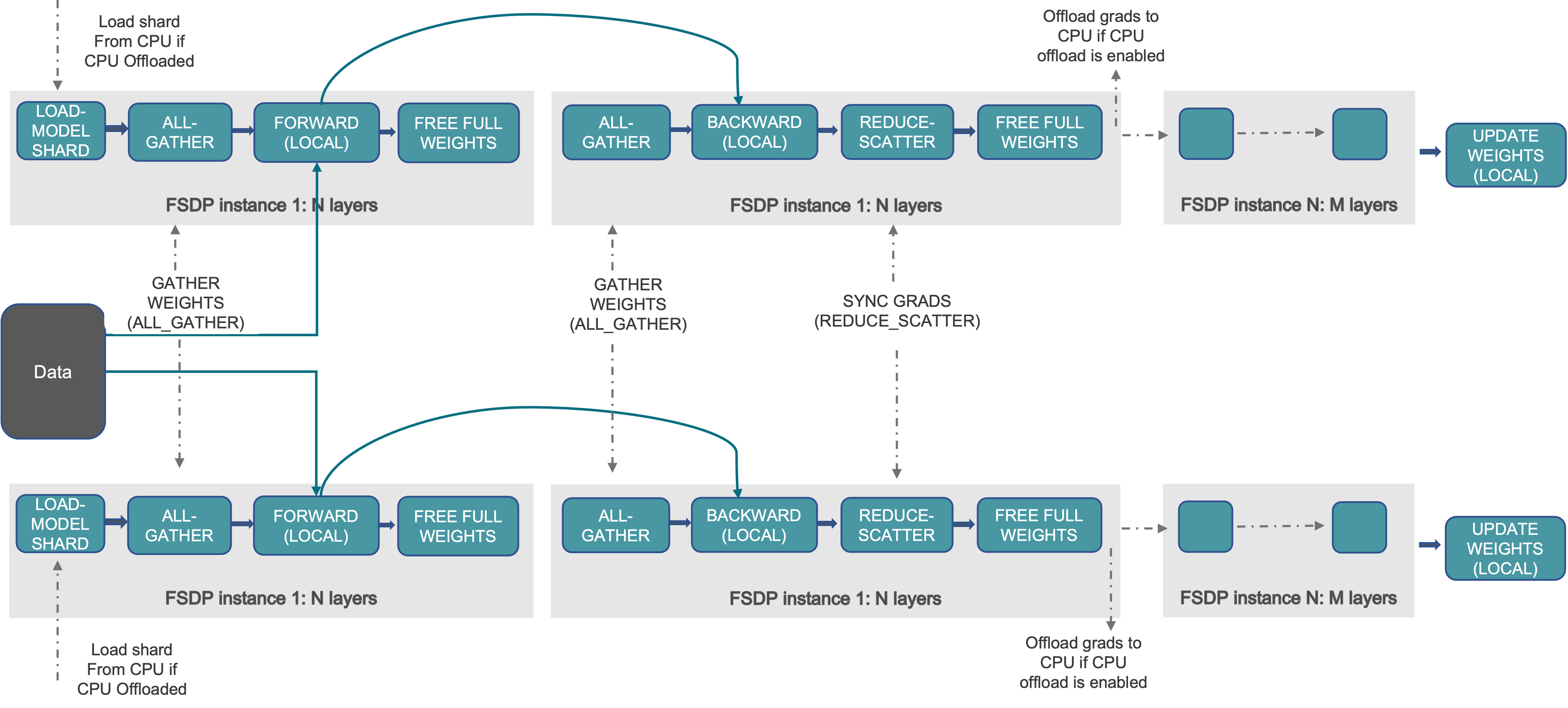
FSDP(完全分片)
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
sharded_module = FSDP(my_module)
- FSDP 是来自 Pytorch 1.11 的特性,FSDP API doc。
- FSDP 的灵感来自 DeepSpeed(
Microsoft发布的深度学习优化库,其核心是通过 ZeRO 优化显存) 和 FairScale(Meta发布的用于高性能和大规模训练的 PyTorch 扩展库)。 - 通过跨数据并行工作程序分片模型的 parameters,gradients,optimizer states,打破模型分片的障碍。
ZeRO
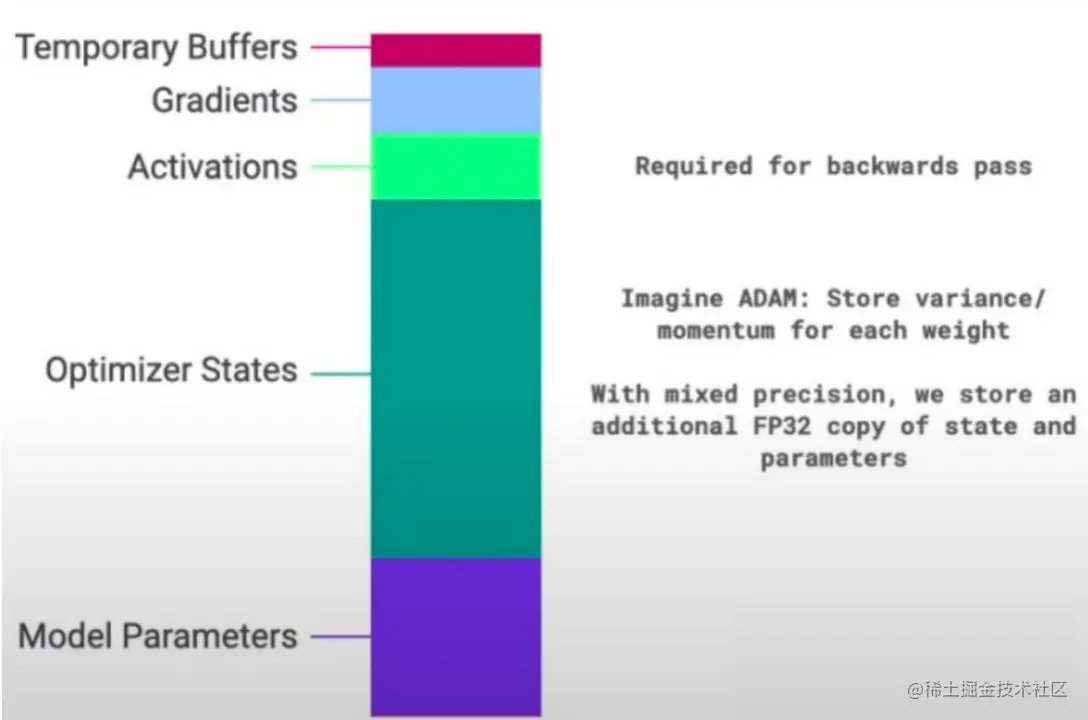
盘点一下 GPU 显存都去哪了:
- Model States
- Optimizer States:优化器状态,例如 ADAM 优化器要求为每一个 weight 保存一份 momentum 和 variance。
- Gradients:梯度
- Model Parameters:模型的权重参数 weight。
- Residual States
- Temporary Buffer:临时缓冲空间,为提升跨设备通信的吞吐量,需要临时申请的空间。例如梯度 all-reduce 时候需要把所有梯度拷贝到一个集中的缓冲区。
- Memory Fragmentation:内存碎片。首先,GPU不存在虚拟内存的概念,申请的内存就是物理内存。其次,Pytorch 这种动态图 AI 框架,训练过程会进行频繁的申请和释放内存,因此会产生大量内存碎片。
- Acivations:激活值,forward 计算得到的中间结果,到 backward 计算的时候需要使用。Acivations 与 batch size、sequence lenth 都存在线性关系。
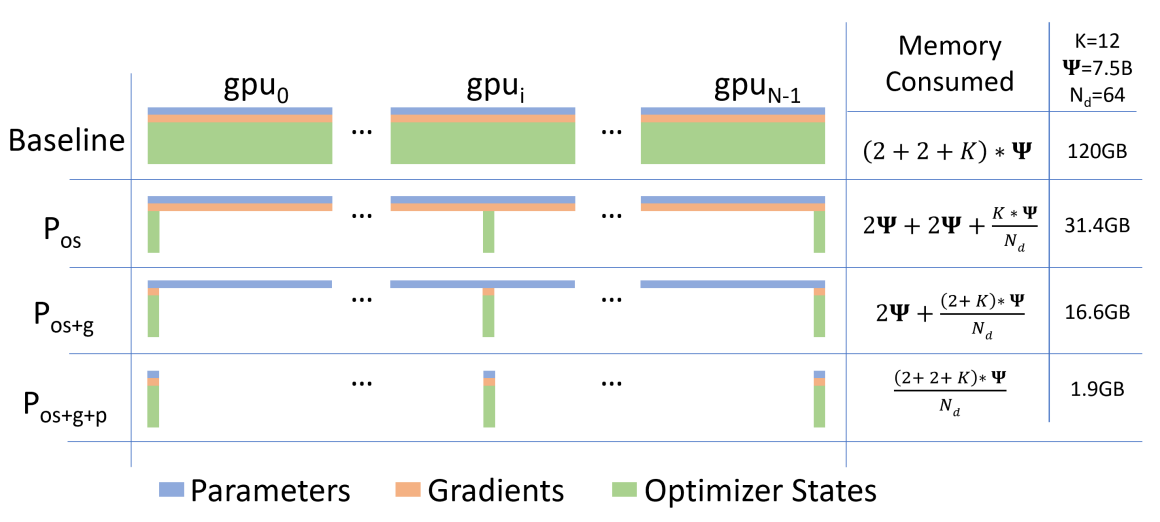
ZeRO-1 : Optimizer States Sharding(P os)
ZeRO-2 : Optimizer States & Gradients Sharding(P os+g)
ZeRO-3 : Optimizer States & Gradients & Parameters Sharding(P os+g+p)
ZeRO1 和 ZeRO2 没有带来额外的通讯,因为 all-reduce 就是这么实现的。
ZeRO3 确实带来了额外的通讯,因为权重计算时候需要从其他卡上取,通信量大约是先前的 1.5 倍,不过理想情况下可以通过异步的方式把这些时间隐藏起来。
总体思想:用带宽换取宝贵的显存空间。
ZeRO-Offload
一共就这么几张卡,显存不够用?考虑”借“用 Host 的内存。
ZeRO-Infinity
面向大规模
Allreduce算法
All-Reduce = Reduce-Scatter + All-Gather
模型并行
TP
- TP 为层内并行,如卫星图片处理需要靠 TP 解决。
- 一般机内使用 TP,机间使用数据并行。
- 最常见的是 MatMul 算子并行,扩展到 Embedding、MLP、Transformer 等算子并行。
- 需要注意随机性问题,注意带有随机性算子的随机种子设置。
https://pytorch.org/docs/stable/distributed.tensor.parallel.html
数学原理
MatMul 算子并行
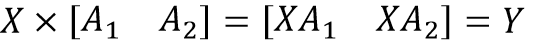
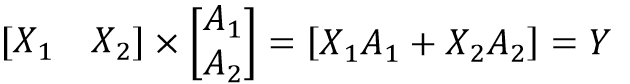
组合减小通信开销
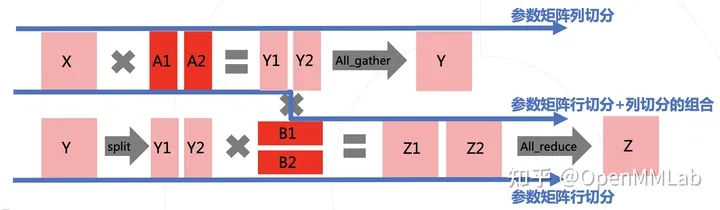
我们发现把两次切分组合在一起,那么上面一行最后的 all_gather 和下面一行最开始的 spllit 就可以省去,减少了冗余的集合通信开销。而 Transformer 的结构天然支持这种组合。
Transformer 算子并行
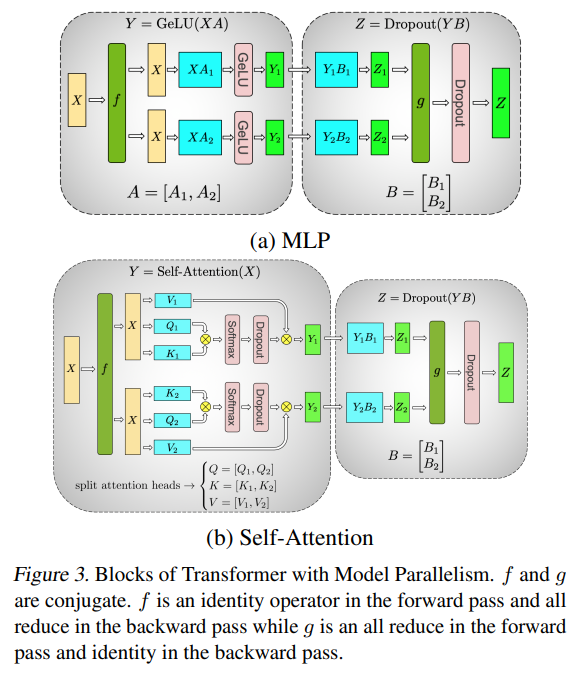
上图中深绿色的 f 和 g 代表集合通信的环节。
与上一小节类似的,我们把 attention heads(Q、K、V)分别进行列切分,经过矩阵乘和 Softmax、Dropout 后得出的 Y 依然是满足 Y = Y1 + Y2 的,然后再对 B 进行切分,完成后半部分的 Dropout 计算后在进行一次集合通信即完成一次 self-attention 的计算。
Loss 损失并行
张量重排
随机控制
Embedding
张量自动并行
MindSpore 保存和加载模型(HyBrid Parallel模式)
https://www.mindspore.cn/tutorials/experts/zh-CN/r2.0/parallel/save_load.html
MindSpore 分布式并行
https://www.mindspore.cn/docs/zh-CN/r2.0/design/distributed_training_design.html?
MindSpore 分布式并行总览
https://www.mindspore.cn/tutorials/experts/zh-CN/r2.0/parallel/introduction.html
- 由模型定义脚本转换成带有切分策略的计算图。
- 为每个未配置切分策略的算子枚举可行的策略。
- 枚举每条边的重排布策略和相应的代价。
- 由一配置策略的算法出发,传播到整张计算图。
PP
以 Megatron-LM 为例介绍流水线并行。
Naive pipeline parallelism
Gpipe 模式
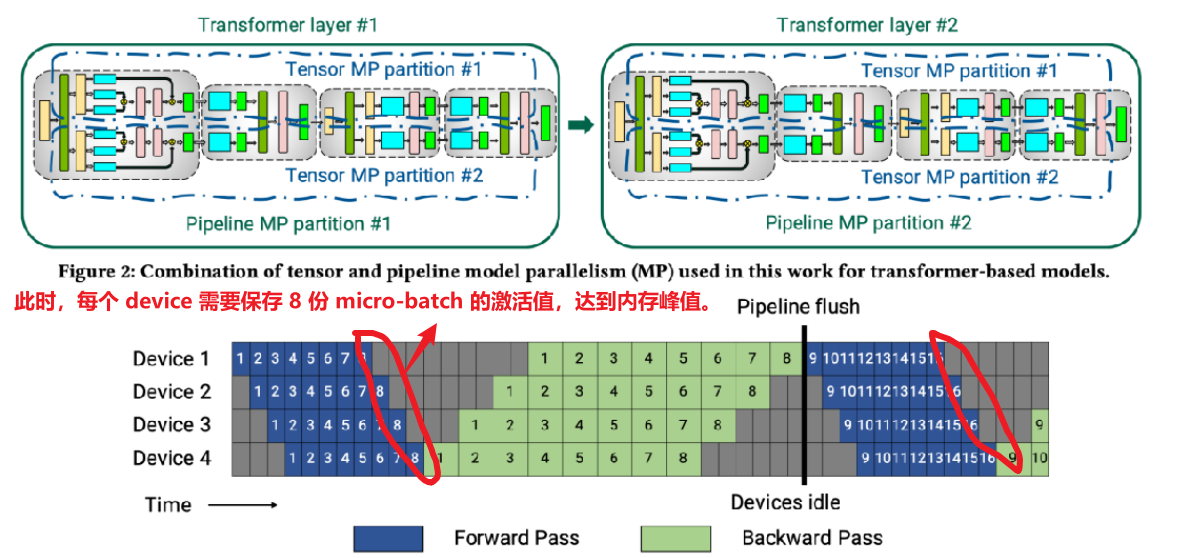
缺点一:空泡率高。假设 m 代表 micro-batch 数量,p 代表 pipeline stages,则要求 m 远大于 p,才能有效降低空泡率。又由于缺点二导致 m 的上限非常有限。
缺点二:内存峰值高。m 个 micro-batch 反向算梯度的过程,都需要之前前向保存的激活值,所以在 m 个 mini-batch 前向结束时,达到内存占用的峰值。Device 内存一定的情况下,m 的上限明显受到限制。
重计算
PipeDream 1F1B 模式(非交错 Schedule)
通过合理安排前向和反向过程的顺序,在 step 中间的稳定阶段,形成 1 前向 1 反向 的形式,称为 1F1B 模式。
每个 Device 上最少只需要保存 1 份 micro-batch 的激活值,最多也只需要保存 p 份激活值。
这种模式比 GPipe 更节省内存。然而,它需要和 GPipe 一样的时间来完成一轮计算。
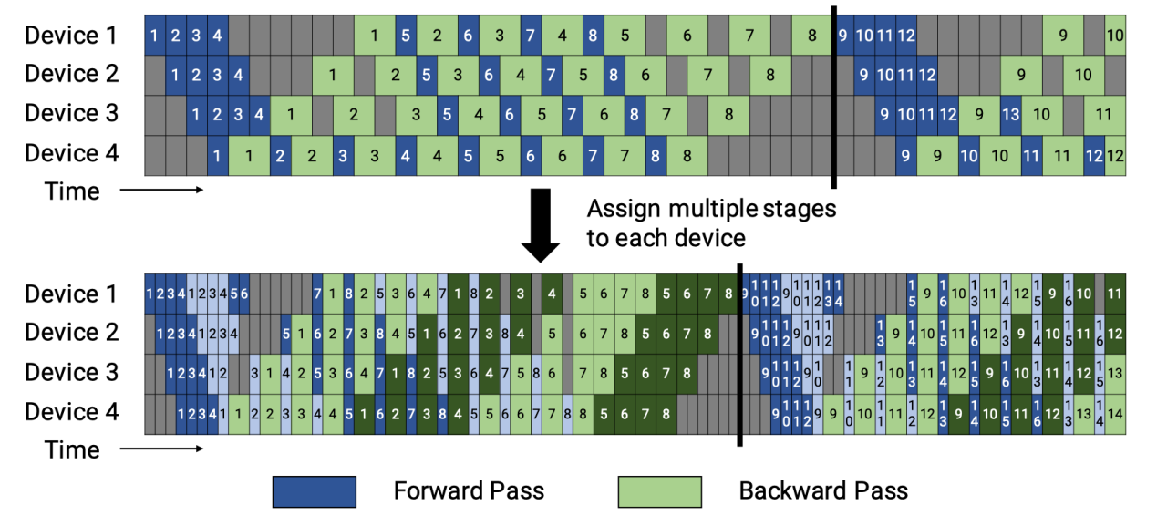
权重隐藏???
Virtual pipeline 模式(交错 Schedule)
原方案:设备1拥有层1-4,设备2拥有层5-8,以此类推。
新方案:在设备1有层1,2,9,10,设备2有层3,4,11,12,以此类推。
按照这种方式,Device之间的点对点通信次数(量)直接翻了 virtual_pipeline_stage 倍,但空泡比率降低了。
virtual pipeline 带来的 空泡占比降低 和 step e2e 时间缩短的优势并不是凭空得来,Megatron-2 做出这样改进的本钱主要是在 DGX-box 中,NVLINK 带宽高,通信带来的 overhead 不是很明显。
(要求:micro-batch 的数量是流水线阶段的整数倍。)
混合并行
DLRM(张量并行 + 数据并行)
- table-wise 切分模式:不同目录的特征切分到不同的卡上
- colume-wise 切分模式:不同目录特征合成一个大表,然后按照列进行切分
为什么只对 Embedding 层进行张量并行?
答:Embedding 层(将输入数据 or 离散特征映射到高维的向量中)在推荐模型中非常重要,参数量也非常大,可以到 TB 级别。
Megaton-LLM(张量并行 + 流水线并行)
附录
相关论文
- 【25 Jul 2019】【google】GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
- 【8 Jun 2018】【microsoft】PipeDream: Fast and Efficient Pipeline Parallel DNN Training
- 【28 Jun 2020】PyTorch Distributed: Experiences on Accelerating Data Parallel Training
- 【13 Mar 2020】Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- 【13 May 2020】ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- 【18 Jan 2021】ZeRO-Offload: Democratizing Billion-Scale Model Training
- 【16 Apr 2021】ZeRO-Infinity: Breaking the GPU Memory Wallfor Extreme Scale Deep Learning
- 【23 Aug 2021】Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
官方文档
- Massively Scale Your Deep Learning Training with NCCL 2.4
- Collective Operations
- GETTING STARTED WITH DISTRIBUTED DATA PARALLEL
- 【March 14, 2022】Introducing PyTorch Fully Sharded Data Parallel (FSDP) API
知乎文章
- 数据并行Deep-dive: 从DP 到 Fully Sharded Data Parallel (FSDP)完全分片数据并行
- DeepSpeed之ZeRO系列:将显存优化进行到底
- Megatron-LM 中的 pipeline 并行
- 手把手推导Ring All-reduce的数学性质
- https://zhuanlan.zhihu.com/p/450689346
B 站视频
其他文章
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 nz_nuaa@163.com